Code Request
Filling out this form will grant you access to all of the code on this site. In addition, you will join our mailing list, and we'll send you periodic updates regarding new articles.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
June 22, 2023
Scraping Yelp Businesses with Python
How to Web Scrape Yelp Businesses
Click here to download this post's source code
How to Web Scrape Yelp Businesses

Photo by piotr szulawski on Unsplash
Table of Contents
Introduction
I recently wrote an article regarding how to scrape yellowpages.com for business information. Now we're going to do the same thing, but with Yelp.
Yelp is a "community-driven platform that connects people with great local businesses." In other words, it is the perfect site to scrape to gather comprehensive information about businesses in a specific industry and/or location.
Getting started
In this article, we'll scrape business listings for:
- Business Name
- Location
- Opening Time
- Number of Reviews
- Phone Number
- Website
We only explain how to scrape Business Name, Phone number, and Website in this article. To follow along and get the other values, please download the source code. For the following Python code to work, you'll need to install several libraries using pip:
pip install selenium
pip install webdriver_manager
pip install bs4
pip install pandas
pip install tqdm
In case you don't already know, Selenium is a web automation tool that allows us to scrape websites for information. Now, let's make sure that everything is set up correctly by using Selenium to go to yelp.com:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
import pandas as pd
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get('https://www.yelp.com')
If that worked correctly, you should see a new window that looks something like this:
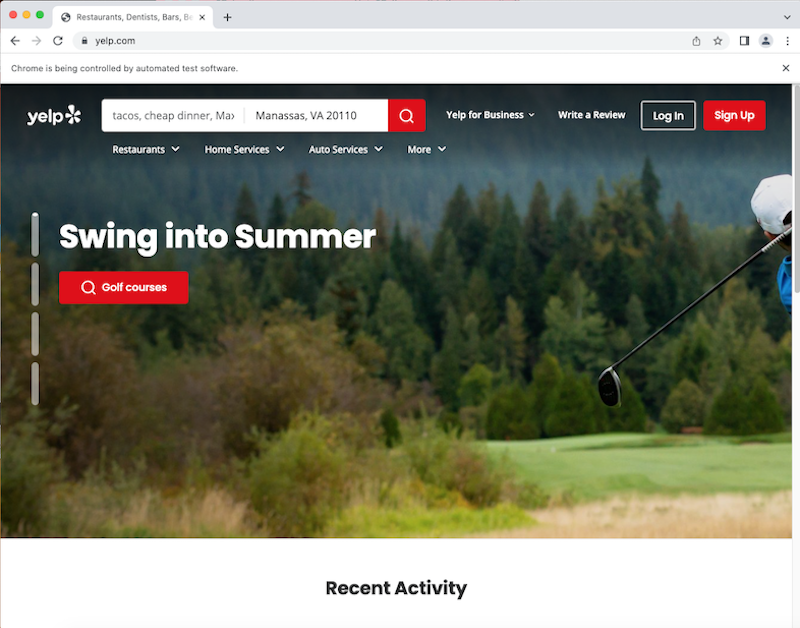
Yelp's search tool is based on string queries and locations. The search URL format is as follows:
https://www.yelp.com/search?find_desc=enter string query here&find_loc=enter location here.
If I wanted to search for Burgers in California, the URL would be this: https://www.yelp.com/search?find_desc=Burgers&find_loc=CA.
Now let's get the search results from this and the following pages.
Scraping the Search Results
Let's start by going to the search result page.
all_urls = []
location = 'CA'
category = 'Burgers'
search_url = 'https://www.yelp.com/search?find_desc={}&find_loc={}'
formatted_search_url = search_url.format(category.replace(' ', '+'), location.replace(',', ','))
driver.get(formatted_search_url)
We used .format to insert the category and location data into the search URL, and then going to search page with Selenium.
Yelp.com's search results contain <a> tags which point to business listing pages. The class of these elements can be found using the Inspector Tool. Let's extract all of those tags by their class value.
for x in driver.find_elements(By.CLASS_NAME, 'css-19v1rkv'):
new_href = x.get_attribute('href')
all_urls.append(new_href)
print(all_urls)
We got the href attribute of all the elements with the class css-19v1rkv. The result:
['https://www.yelp.com/adredir?ad_business_id=iLrsEZB2fZK7x3PeZ4qi4g&campaign_id=4XpnigehR-aI1MBGRmWYfA&click_origin=search_results&placement=vertical_0&placement_slot=0..., ...]
Ok, so that's all of the items on this page. What about the other pages for this search? To get those, let's get the page counter on the results page:
page_count_xpath = '//*[@class=" border-color--default__09f24__NPAKY text-align--center__09f24__fYBGO"]//*[@class=" css-chan6m"]'
current, end = driver.find_element(By.XPATH, page_count_xpath).text.split(' of ') # page count
and split the resulting text string by the "of" (1 of 4) to get the current page and ending, final page. Then, we increment through the pages until ending up at the last one, saving all the URLs as we work our way through the pages:
...
page_count_xpath = '//*[@class=" border-color--default__09f24__NPAKY text-align--center__09f24__fYBGO"]//*[@class=" css-chan6m"]'
driver.get(formatted_search_url)
while True:
for x in driver.find_elements(By.CLASS_NAME, 'css-19v1rkv'):
new_href = x.get_attribute('href')
all_urls.append(new_href)
try:
current, end = driver.find_element(By.XPATH, page_count_xpath).text.split(' of ') # page count
print('Page {} of {}'.format(current, end))
if current != end:
next_page = driver.find_element(By.XPATH, '//*[contains(@class, "next-link")]').get_attribute('href')
driver.get(next_page)
else:
break
except Exception as E:
print('EXCEPTION:', driver.current_url)
print(E)
break
We keep on extracting URLs and going onto the next page until there are no pages left (when current = end, or the counter string looks something like "# of #", "20 of 20"). We add all of the URL results to an all_urls list as we go through the pages.
Finally, now that we've extracted all of the URLs, let's save them to a file, yelp_urls.csv. To do this, we need a library called pandas, which we installed earlier.
df = pd.DataFrame(list(set(all_urls))) # gets rid of duplicates and writes to pandas dataframe, then file
df.to_csv('yelp_urls.csv')
Scraping Business Listings
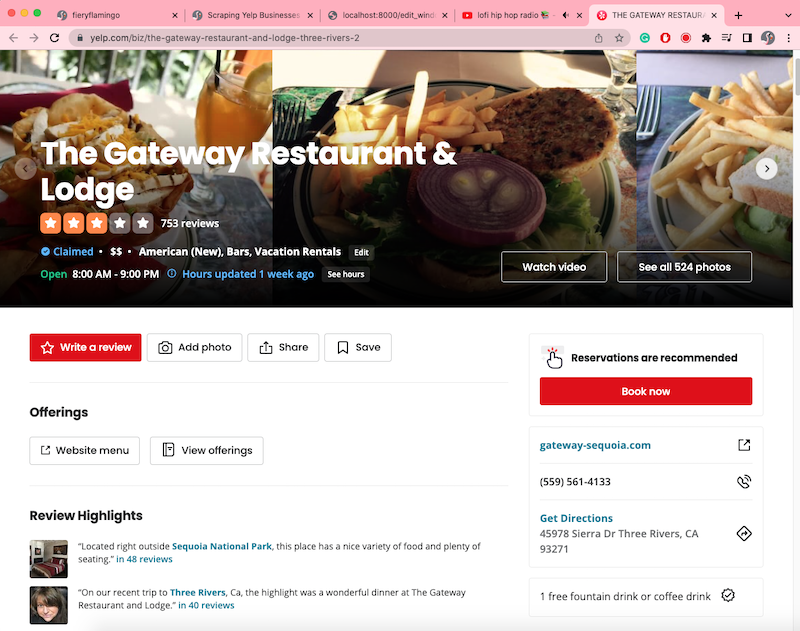
Now that we have the URLs written to a csv file, let's scrape some of them to get important data. First, we need to read the file and set up our Selenium driver again:
# a new file
import pandas as pd
from bs4 import BeautifulSoup
from urllib.parse import unquote
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from tqdm import tqdm
all_data = []
all_urls = pd.read_csv('yelp_urls.csv')['0'][:10] # first 10 for testing purposes
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get(all_urls[0])
Most of the data we want is stored inside this area on the webpage:
which includes the business' website, phone number, and address. Extracting this section's HTML is trivial since it's inside a special "aside" tag.
main_section = driver.find_element(By.TAG_NAME, 'aside').get_attribute('innerHTML')
Next, we'll want to parse this element's html for the aforementioned values. This function does that:
def parse(html):
business_website, business_phone_number, directions = '', '', ''
all_sections = BeautifulSoup(html, features='html.parser').find_all('section', recursive=False)
c = []
for section in all_sections:
b = section.find('div', recursive=False)
if b:
c = b.find_all('div', {'class': 'css-1vhakgw'}, recursive=False)
if c:
break
for x in c:
label = x.find('p', {'class': 'css-na3oda'})
if not label:
label = x.find('a', {'class': 'css-1idmmu3'})
if label:
label = label.text
if label == 'Business website':
business_website = x.find('p', {'class': 'css-1p9ibgf'}).find('a')
if business_website:
business_website = business_website['href']
try:
business_website = unquote(business_website.replace('/biz_redir?url=', '').split('&')[0])
except:
business_website = ''
else:
business_website = ''
elif label == 'Phone number':
business_phone_number = x.find('p', {'class': 'css-1p9ibgf'}).text
elif label == 'Get Directions':
directions = x.find('p', {'class': 'css-qyp8bo'}).text
return business_website, business_phone_number, directions
Whew, that's a big function. Let's break it down into chunks.
all_sections = BeautifulSoup(html, features='html.parser').find_all('section', recursive=False)
c = []
for section in all_sections:
b = section.find('div', recursive=False)
if b:
c = b.find_all('div', {'class': 'css-1vhakgw'}, recursive=False)
if c:
break
The aside tag has several sections inside it, and we're looking to parse the section which contains div elements with the class "css-1vhakgw" (you can look at the HTML in this example yelp listing to see what I mean). We look for those divs, define that list of elements as "c", and then move on.
business_website, business_phone_number, directions = '', '', ''
for x in c:
label = x.find('p', {'class': 'css-na3oda'})
if not label:
label = x.find('a', {'class': 'css-1idmmu3'})
if label:
label = label.text
...
For each of the divs that we found, we're going to look for a label that tells us what type of information it holds (again, these values were found via the Inspector Tool). Now, all we have to do is save the values into their respective categories (business_website, business_phone_number, directions). First business_website. This is inside the for loop by the way
for x in c:
...
if label == 'Business website':
business_website = x.find('p', {'class': 'css-1p9ibgf'}).find('a')
if business_website:
business_website = business_website['href']
try:
business_website = unquote(business_website.replace('/biz_redir?url=', '').split('&')[0])
except:
business_website = ''
else:
business_website = ''
If the label text from before was "Business website", then this code looks for the <a> tag that contains the href value for the business website. If that value is found, the url is reformatted. Otherwise, we assume that no website can be found, and move on.
if label == 'Business website':
...
elif label == 'Phone number':
business_phone_number = x.find('p', {'class': 'css-1p9ibgf'}).text
If instead the label is "Phone Number", the code will look for that text. Similarly, if the label is "Get Directions", this code is run to get the text there.
elif label == 'Get Directions':
directions = x.find('p', {'class': 'css-qyp8bo'}).text
That's the parse function! Let's use it to extract information from our webpage:
url = 'https://www.yelp.com/biz/the-gateway-restaurant-and-lodge-three-rivers-2'
driver.get(url)
main_section = driver.find_element(By.TAG_NAME, 'aside').get_attribute('innerHTML')
website, phone_number, location = parse(main_section)
# https://gateway-sequoia.com, (559) 561-4133, 45978 Sierra Dr Three Rivers, CA 93271
Now, to iterate through the URLs:
...
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
for url in tqdm(all_urls):
driver.get(url)
try:
main_section = driver.find_element(By.TAG_NAME, 'aside').get_attribute('innerHTML')
data = parse(main_section)
website, phone_number, location = data
all_data.append(data)
except:
pass
And to save the file
# may have to install openpyxl. pip install openpyxl
df = pd.DataFrame(all_data, columns=['Business Website', 'Business Phone Number', 'Business Address'])
df.to_excel('final.xlsx', index=False)
That's it! Thanks for reading till the end. If you want the rest of the code, you can find it here. There are two files: get-yelp-urls.py, which covers the first part of the process, and yelp-business-data-from-urls.py, which scrapes the business listing pages (like we did here, only much more thorough). Enjoy!