Feb. 21, 2023
Basics of Static Web Scraping with Python Requests
Python, Requests, BeautifulSoup, and more!
Learn how to scrape static websites with Python's requests library and bs4.

Photo by Markus Spiske on Unsplash
What is Web Scraping?
For our purposes, web scraping is the process by which we can extract data from websites, hopefully in an automated fashion.
The data that can be gathered through even a simple technique such as the one shown in this article can prove to be insanely useful. You can gather data to
- Train machine learning models
- Automatically search the web for keywords or articles related to a topic of interest
- Gather stock market data (and other proprietary information)
- Monitor a webpage for changes.
For one reason or another, in this age of big data, web scraping is essential. Knowing how to scrape the web is a vital source of information for many companies worldwide. Today we'll be covering the basics of how to scrape static webpages with Python's requests library. We'll also interpret that data with BeautifulSoup.
Of course, some websites don't like to be scraped; if you'd like to learn more about a website's preference towards web scraping, here is an article about the importance of the robots.txt file.
Static vs Dynamic Pages
First of all, what do we mean by "static"?
A static webpage is delivered to the user exactly the way it is stored: after the files needed to load the site are sent, no additional information is requested from the server. A simple HTML page with no Javascript would qualify as a static site: after the HTML data is sent to the browser, no other information is requested for the server to send.
Dynamic sites are very different. Most sites are dynamic in one way or another; with dynamic sites, additional information is requested from the server. A lot of high-priority websites use this technique to reduce page loading. For example, some pages have smart image loading, where instead of sending the images to load along with the hypertext, they have Javascript to load them. The same concept applies to videos, articles (infinite scrolling effects), product listings, and social media messages.
You need to be able to scrape dynamic sites. YouTube, Netflix, Twitter, Amazon, CNN, Fox, ... the list of dynamic sites goes on!
How to Scrape Static Sites
Scraping static sites is relatively simple with Python. This is because the libraries we'll be using are heavily developed and simplistic. Let's see an example with the requests library.
The requests library, which is a simple HTTP library, comes preinstalled with Python. That means that importing it is as simple as this:
import requests
There are several general limitations to this library:
- It is not built to scrape dynamic content.
- You cannot interact with the webpage (click buttons, perform repetitive tasks, scroll down the page). This makes the requests library unhelpful in web scraping cases that require user interaction.
For now, let's start by scraping a simple, static web page, the index page of example.com .
# import the library
import requests
url = "https://www.example.com"
html = requests.get(url).text
print(html)
and the code will return something like this:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
...
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
I truncated the styling information for this example, but your result will look somewhat similar to this if you run the code snippet above.
The code is requesting the HTML data from the webpage through its URL. It gets the content through the requests.get() function. To convert the output of this function to text, we get the .text attribute. Alternatively, we could've gotten the .content to get the data as bytes.
That's pretty much how you could gather data from a simple static webpage. However, there are times when access to this data is blocked by a password. Here's how you can use the requests library to get that data.
Scraping Password Protected Data
There are HTTP methods for communicating between a client and a server. The two most common are GET and POST.
The GET method, which is one of the most common of these methods, is used to request data from a specified resource. GET requests are sent using the URL, meaning that they are easily viewed by anybody. Information is sent in the format of a query string as name/value pairs. For example, here's some data sent through a GET request: https://www.website.com/home ?name1=value1&name2=value2 . There are two names here: name1 and name2. name1 is assigned the value value1 .
POST requests are a bit more sophisticated. With a POST request, the data that is sent to the server is stored in the request body rather than the request URL . This means that sensitive information cannot be read directly from the URL. Here's an example of what a POST request might look like:
POST /home HTTP/1.1
Host: somesite.com
name1=value1&name2=value2
Login data is normally sent from a client to a server using a POST request. HTTPS is used to ensure that the plaintext password cannot be read by someone intercepting any messages. Now that we know how this login data is sent, let's try to use the requests library to mimic a request with a correct password.
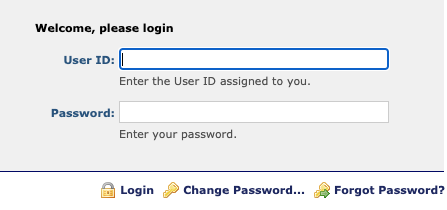
Here's an example login page: https://fieryflamingo.com/login_example/ that was made for this article. We'll try to log in to it using the requests library.
import requests
url = "https://fieryflamingo.com/login_example/"
print(requests.get(url).text)
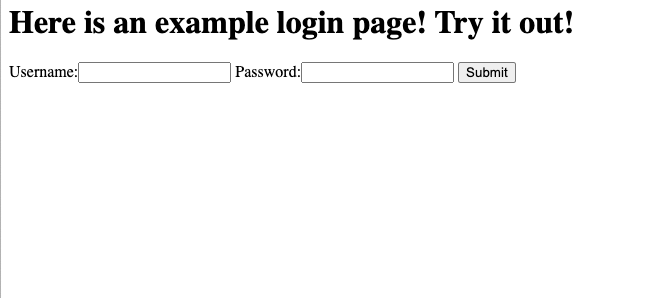
And here's the resulting HTML:
<html>
<h1>Here is an example login page! Try it out!</h1>
<form action = "" method = "post">
<input type="hidden" name="csrfmiddlewaretoken" value="secret_csrf_token">
<tr><th><label for="id_username">Username:</label></th><td><input type="text" name="username" maxlength="200" required id="id_username"></td></tr>
<tr><th><label for="id_password">Password:</label></th><td><input type="password" name="password" required id="id_password"></td></tr>
<input type="submit" value=Submit>
</form>
</html>
From this, we can tell that the form includes two visible fields, named username and password respectively. There is also a hidden field named csrfmiddlewaretoken. To see why some sites use CSRF protection, look at this article .
Basically, on some sites, there is a validator called a CSRF token, or Cross-Site Request Forgery token. It protects against CSRF. CSRF is used to send malicious requests from an authenticated user to a web application. This website uses CSRF protection, which is why we need to gather that information from the form before sending our username and password.
If you look closely, you can also tell that the form utilizes the POST method, where information is sent through the request body. Finally, we know that the form is sending data back to the same page (the action directs it back to the same page, denoted by action = ""). Now that we have the names of these fields, we can set their values.
The only valid username and password for this example are:
- Username: example
- Password: 12345examplepassword
import requests
url = "https://www.fieryflamingo.com/login_example/"
# start a session
s = requests.session()
# visit the page once to get the csrftoken cookie
s.get(url)
# required data to send
# set the csrfmiddlewaretoken to the cookie that we got
payload = {
'username': "example",
'password': "12345examplepassword",
'csrfmiddlewaretoken': s.cookies.get("csrftoken")
}
print('The csrfmiddlewaretoken is: ' payload['csrfmiddlewaretoken'])
# send the payload
req = s.post(url, data=payload, headers = {'Referer': url})
print (req.text)
And here's the result:
You correctly logged in! Here's some text!
If you were to change the username or password to something incorrect (try it!), you would get:
Sorry, incorrect login
The above code works as follows:
- We start a session
- We gather the CSRF cookie and any other hidden fields we need from the site (not all sites have this).
- Then we set a payload, or a dictionary of data, we need send back to the same site. This payload includes our username and password.
- We reuse the same session that we used to get the cookie and send our payload.
BeautifulSoup

Photo by Sigmund on Unsplash .
This article is solely focused on static web scraping .
First, let's try to interpret the HTML data we get with requests .
BeautifulSoup is a Python package for parsing HTML and XML documents. It allows you to specify which part of the HTML document (and what information) you want to use or find. Let's install it with pip.
pip install bs4
Let's see an example of BeautifulSoup in action. I'll create a function named "parse" which takes the HTML as input and returns all the 'p' tags.
In this example, we're using the HTML parser. The parser interprets the HTML code into a format that the library uses to decide things about the HTML data.
# import the libraries
import requests
from bs4 import BeautifulSoup # new library
# our parsing function
def parse(html):
soup = BeautifulSoup(html, "html.parser")
return list(soup.find_all('p')) # get the text of the first element 'p'
url = "https://www.example.com"
html = requests.get(url).text
print(parse(html))
soup.find_all() returns an iterable that contains all the HTML tags that meet the requirements we told it to look for. In this case, we wanted all the "
" tags.
Alternatively, soup.find() would return the first element that meets those requirements. You use it when you are searching for a specific element.
soup.find_all() is what you would use when you want to search through a group of elements.
In the code, we again get the data from www.example.com and pass it into the parse function. This function takes the HTML code and spits out a BeautifulSoup object. From that object, we get and return a list of all the elements we can find that are of the "p" (or paragraph) tag.
[<p>This domain is for use in illustrative examples in documents. You may use this domain in literature without prior coordination or asking for permission.</p>, <p><a href="https://www.iana.org/domains/example">More information...</a></p>]
In this next example, I'll demonstrate searching by class name and id. These attributes can be used to specify that we are looking for elements of a certain class or id. I'll use an example website from this site for that: https://www.fieryflamingo.com/example_page .
# import the libraries
import requests
from bs4 import BeautifulSoup
# our parsing function
def parse(html):
soup = BeautifulSoup(html, "html.parser")
results = soup.find_all('p', {'class': 'example_class'})
return list(results)
url = "https://www.fieryflamingo.com/example_page"
html = requests.get(url).text
print(parse(html))
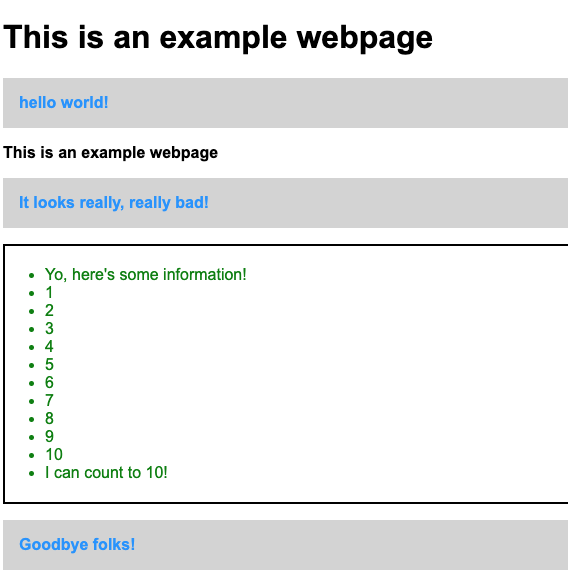
And here's what we get:
[<p class="example_class">hello world!</p>, <p class="example_class">It looks really, really bad!</p>, <p class="example_class">Goodbye folks!</p>]
In this example, I was searching by using the class parameter and giving it the argument "example_class". It returned all the p elements on the page with a class of that name.
Now let's try searching by id:
import requests
from bs4 import BeautifulSoup
# our parsing function
def parse(html):
soup = BeautifulSoup(html, "html.parser")
return soup.find('ul', {'id': 'list_id'})
url = "https://www.fieryflamingo.com/example_page"
html = requests.get(url).text
print(parse(html))
The above code looks for a ul (list) tag with the id list_id . Here's the result:
<ul id="list_id">
<li>Yo, here's some information!</li>
<li>1</li>
<li>2</li>
<li>3</li>
<li>4</li>
<li>5</li>
<li>6</li>
<li>7</li>
<li>8</li>
<li>9</li>
<li>10</li>
<li>I can count to 10!</li>
</ul>
You'll notice that the return value includes the li tags. To get each of the tags as a list we can do this instead:
# our parsing function
def parse(html):
soup = BeautifulSoup(html, "html.parser")
value = soup.find(id='list_id')
return list(value.find_all('li'))
And this returns the li elements inside the ul tag as a list:
[<li>Yo, here's some information!</li>, <li>1</li>, <li>2</li>, <li>3</li>, <li>4</li>, <li>5</li>, <li>6</li>, <li>7</li>, <li>8</li>, <li>9</li>, <li>10</li>, <li>I can count to 10!</li>]
We can also extract attributes (like text) from each of these li tags, for example. One way we can do this is by iterating through each of the li tags and getting their values.
# our parsing function
def parse(html):
soup = BeautifulSoup(html, "html.parser")
value = soup.find(id='list_id')
return list([x.text.strip() for x in value.find_all('li')])
And that result is much cleaner:
["Yo, here's some information!", '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'I can count to 10!']
Another script I commonly use is to get the text from a website and delete everything else. I do this mainly for data collection. Here's how you can change our function to accomplish that.
import requests
from bs4 import BeautifulSoup
# our parsing function
# scrape the text from HTML
def parse(html):
soup = BeautifulSoup(html, "html.parser")
for unwanted_tags in soup(["script", "style"]):
unwanted_tags.extract()
# get remaining text from the soup object
text = soup.get_text()
# break this text into remaining lines
# get rid of the trailing spaces at the end of each line
lines = (line.strip() for line in text.splitlines())
# now get rid of blank lines (join the lines that are not blank)
text = '
'.join(line for line in lines if line)
return text
url = "https://www.fieryflamingo.com/example_page"
html = requests.get(url).text
print(parse(html))
And the Python BeautifulSoup code returns:
This is an example webpage
hello world!
This is an example webpage
It looks really, really bad!
Yo, here's some information!
1
2
3
4
5
6
7
8
9
10
I can count to 10!
Goodbye folks!
This was a brief introduction to BeautifulSoup and the Requests library. I hope that you found this helpful.